Spark Execution Plan Part 1
Einführung
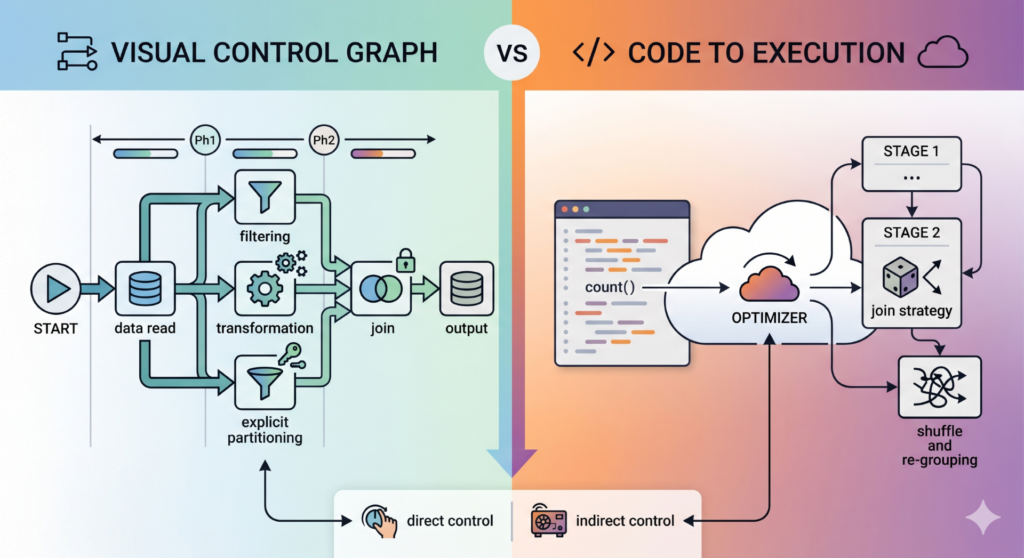
Wer aus der Ab Initio Welt kommt, ist es gewohnt, die Datenpipeline von Anfang an vollständig unter Kontrolle zu haben. Man sieht im Graph genau, wie Daten gelesen werden, welche Komponenten mit welcher Parametrisierung benutzt werden, wann eine Partitionierung stattfindet und wann eine neue Phase der Ausführung startet. Jeder Schritt im Verarbeitungsprozess wird selbst konfiguriert und ist vollständig nachvollziehbar.
In Spark fühlt sich das zunächst etwas anders an. Man schreibt Code, führt Transformationen und Aktionen aus, aber wie dann tatsächlich Code ausgeführt wird, entscheidet der Optimizer im Hintergrund. Wann Daten wirklich gelesen werden, welche Join-Strategie gewählt wird und ob ein Shuffle stattfindet, ist nur noch indirekt kontrollierbar.
Visualisierung erstellt mit Unterstützung von KI (Gemini)
Die dabei in Spark ablaufenden Hintergrundprozesse sind natürlich kein Zufall, sondern das Ergebnis eines mehrstufigen Optimierungsprozesses. Spark übersetzt den Code zunächst in einen logischen Plan und transformiert diesen anschließend in einen physischen Ausführungsplan.
Dieser physische Ausführungsplan, der sogenannte Execution Plan, ist die konkrete Ausführungsrealität der Pipeline. Wer Spark wirklich verstehen und Performance gezielt beeinflussen will, muss genau hier ansetzen, beim Execution Plan.
Nach dieser theoretischen Einordnung stellt sich die entscheidende Frage:
Wie sieht dieser Execution Plan in der Praxis aus?
Execution Plan in der Praxis
Um das greifbar zu machen, betrachten wir ein konkretes Beispiel. Wir bauen eine typische Data-Engineering-Situation nach: Eine große Transaktionstabelle wird mit einer Kundentabelle verknüpft, anschließend werden einige fachliche Berechnungen sowie Aggregationen durchgeführt.
In Ab Initio würde man diesen Use Case als klar strukturierten Graphen modellieren: Datenquellen, Join-Komponente, Transformationsschritt, Aggregation. In Spark reicht dafür zwar eine Handvoll Codezeilen. Es zeigt sich dann jedoch, wie Spark aus einer scheinbar simplen ETL-Pipeline einen mehrstufigen Execution Plan mit mehreren Phasen und Datenbewegungen erzeugt.
Für unseren Use Case erzeugen wir eine große Transaktionstabelle mit 30 Millionen Zeilen und eine Kundentabelle mit rund 1 Million Kunden. Zusätzlich bauen wir bewusst einen dominanten Join-Key ein: 70% der Transaktionen gehören zu einem “VIP_CUSTOMER”.
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
spark.conf.set("spark.sql.adaptive.enabled", "false")
df_transactions = (
spark.range(30_000_000)
.withColumnRenamed("id", "transaction_id")
.withColumn(
"customer_id",
F.when(F.rand() < 0.7, F.lit("VIP_CUSTOMER"))
.otherwise((F.rand() * 1_000_000).cast("string"))
)
.withColumn("amount", F.rand() * 1000)
)
df_customers = (
spark.range(1_000_000)
.withColumnRenamed("id", "customer_id")
.withColumn("customer_id", F.col("customer_id").cast("string"))
)
vip = spark.createDataFrame([Row(customer_id="VIP_CUSTOMER")])
df_customers = vip.union(df_customers)
total_sum = (
df_transactions
.join(df_customers, "customer_id")
.withColumn("processed_amount", heavy_udf(F.col("amount")))
.agg(F.sum("processed_amount"))
.collect()
)
Die Spark-Konfiguration ist dabei bewusst gewählt:
- Broadcast Joins sind deaktiviert. Spark darf die deutlich kleinere Kundentabelle beim Join also nicht einfach auf alle Worker-Nodes kopieren.
- Adaptive Query Execution ist deaktiviert. Dadurch sehen wir den elementaren physischen Plan ohne dynamische Laufzeitkorrekturen.
Die Pipeline ist bewusst einfach gewählt: Zwei Datenquellen, ein Join und eine finale Aggregation. Sobald jedoch eine Action wie .collect() ausgeführt wird, übersetzt Spark die wenigen Transformationen in einen komplexen physischen Ausführungsplan. Es genügt also nicht bloß, den Code zu betrachten. Erst der Execution Plan zeigt, wie die Daten konkret partitioniert werden, welche Prozesse parallel laufen und wie die Join-Strategien durchgeführt werden.
Der Execution Plan kann durch folgenden Befehl ausgegeben werden:
total_sum.explain("formatted")
Wir zeigen hier aufgrund der Komplexität nicht den gesamten Plan, sondern stattdessen nur die für das Verständnis wichtigsten Teile des Execution Plans. Der Execution Plan lässt sich am besten von unten nach oben lesen.
== Physical Plan ==
HashAggregate
+- Exchange
+- HashAggregate
+- Project
+- BatchEvalPython
+- SortMergeJoin
:- Exchange hashpartitioning(customer_id, 8)
+- Exchange hashpartitioning(customer_id, 8)
Die entscheidenden Operatoren sind hier:
- Exchange hashpartitioning(customer_id, 8): Dieser Operator beschreibt die Partitionierung der Daten basierend auf dem Join-Key customer_id. Da Broadcast Joins deaktiviert sind, müssen beide Seiten des Joins über einen Shuffle nach dem gleichen Partitionierungsschlüssel aufgeteilt werden. In Ab Initio entspricht dieser Schritt der Benutzung einer Partition By Key Komponente, die ebenfalls einen Datenstrom, basierend auf einem Schlüsselfeld in mehrere Partitionen aufteilt.
- SortMergeJoin: Nach der Partitionierung der beiden Seiten führt Spark den Join als SortMergeJoin aus. Dieser effiziente Algorithmus ist selten das Problem, teuer ist der Shuffle, der als Grundlage dafür benötigt wird.
- BatchEvalPython: Nach dem Join wird die Python-UDF ausgeführt. Spark kann diese Logik nicht wie native SQL-Ausdrücke vollständig optimieren. Die Daten müssen deshalb direkt in Python verarbeitet werden, was zusätzlichen Overhead erzeugt. In Ab Initio wäre das vergleichbar mit einer Komponente wie Run Program, in der externer Code außerhalb der stark optimierten Standardkomponenten läuft.
- HashAggregate/Exchange: Die Aggregation läuft nun in zwei Teilschritten ab. Zuerst aggregiert Spark lokal pro Partition, führt dann einen weiteren Exchange Schritt aus, in dem die Teilergebnisse auf eine Worker-Node transferiert werden. Dort findet dann der finale Aggregationsschritt statt.
Der zentrale Unterschied zwischen Ab Initio und Spark liegt dabei in der Herangehensweise beim Aufbau der Transformationslogik:
In Ab Initio wird jeder Teilaspekt des Datenflusses explizit modelliert: Partitionierung und Join-Parametrisierung sind Teil des Graphen und vollkommen vom Entwickler gesteuert. In Spark hingegen beschreibt der Entwickler lediglich die Transformationen, während die physische Ausführung erst zur Laufzeit durch den Optimizer entsteht und im Execution Plan sichtbar wird.
Genau deshalb ist der Execution Plan das entscheidende Werkzeug, um Spark wirklich zu verstehen. Er zeigt nicht nur, was passiert, sondern vor allem, wie es passiert und wo die tatsächlichen Kosten entstehen. Wer ihn lesen kann, erkennt Shuffles, Join-Strategien und Engpässe, bevor sie zum Problem werden.
Ausblick
In unserem Use Case ist zudem ein weiterer kritischer Faktor eingebaut: 70% der Daten entfallen auf einen einzigen Join-Key. Diese ungleichmäßige Verteilung ist im Execution Plan zunächst nicht offensichtlich, kann aber zur Laufzeit massive Performanceprobleme verursachen. Genau dieses Phänomen, Data Skew und die Lösung dafür, betrachten wir im nächsten Teil.