Enterprise Datenplattform mit Databricks Part 3
Einführung
Willkommen zurück zu unserer Blog-Serie rund um den Aufbau moderner Enterprise-Datenplattformen!
In unserem letzten Beitrag haben wir gezeigt, wie wir Rohdaten aus APIs flexibel und ausfallsicher in den Bronze-Layer unserer Databricks-Plattform laden. Doch Rohdaten allein schaffen noch keinen geschäftlichen Mehrwert. Der nächste logische Schritt ist die Datentransformation.
Wie wir mit dbt und der Medaillon-Architektur Rohdaten in wertvolle Business-Insights verwandeln, zeigen wir in diesem Beitrag auf.
Visualisierung erstellt mit Unterstützung von KI (Gemini)
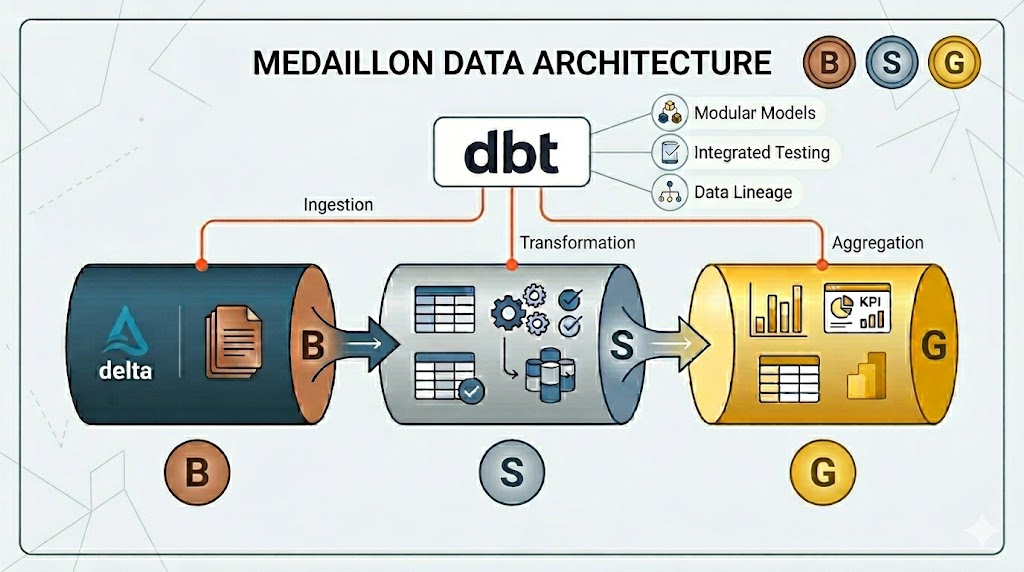
Medaillon-Architektur
Sobald die Daten im Delta Format Layer persistiert sind, wechselt unser Fokus von Datenbeschaffung zur Datentransformation mit dbt. Während wir Python und Spark für die Anbindung der APIs genutzt haben, ist dbt nun das Werkzeug, um die Transformationslogik innerhalb von Databricks zu implementieren.
Dabei greifen wir auf die bewährte Medaillon-Architektur zurück: Wir starten mit den groben Rohdaten aus den Quellsystemen (Bronze Layer) und verarbeiten sie Schritt für Schritt (Silver Layer) bis zum fertigen Endprodukt (Gold Layer). Im folgenden gehen wir detaillierter auf die einzelnen Schichten der Medaillon-Architektur ein:
- Bronze Layer (Raw Data): Dies ist unsere „Single Source of Truth“. Hier speichern wir die Daten bis auf minimale technische Korrekturen exakt so, wie sie von der API geliefert werden. Der Fokus liegt dabei auf der Vollständigkeit, Revisionssicherheit und Auditierbarkeit. Durch das Delta-Format stellen wir sicher, dass wir jederzeit auf frühere Versionen zurückgreifen können (Time Travel), falls fachliche Logiken im Nachgang angepasst werden müssen.
- Silver Layer (Cleansed): In dieser Schicht findet die fachliche Transformation statt. Wir harmonisieren Datentypen, implementieren Prioritätsregeln bei Duplikaten aus verschiedenen Quellsystemen, erstellen Business-Rules und überführen die Rohdaten so in das angestrebte Ziel-Datenmodell. Das Ergebnis ist ein bereinigtes, normalisiertes und konsistentes Datenmodell.
- Gold Layer (Business Ready): Die finale Stufe der Transformation ist rein auf den geschäftlichen Nutzen ausgerichtet. Je nach Anwendungsfall werden hier Datenaggregationen für Reportinganforderungen durchgeführt oder geschäftskritische Kennzahlen (KPIs) berechnet. Der Gold Layer liefert dabei Tabellenformate, die direkt für Reporting Tools wie Power BI oder Tableau optimiert sind.
Warum dbt für uns im Cloud-Stack unverzichtbar ist
Während Databricks die Rechenleistung und die Speicherarchitektur bereitstellt, fungiert dbt für uns als das “Gehirn” für die Datentransformation.
- Modularität & Macros: Anstatt riesige SQL-Skripte zu schreiben, zerlegen wir die Logik in kleine und wiederverwendbare Bausteine (Models). Mit Jinja-basierten Macros automatisieren wir wiederkehrende Aufgaben – ein Prinzip der Softwareentwicklung, das die Wartbarkeit massiv erhöht.
- Integriertes Testing-Framework: Qualität ist kein Zufallsprodukt. Wir definieren Tests direkt in den YAML-Konfigurationen der Modelle. dbt prüft bei jedem Build automatisch auf unique, not_null oder Referenzintegrität. Schlägt ein Test fehl, wird der nachfolgende Prozess gestoppt, bevor fehlerhafte Daten im Reporting landen.
- Automatisierte Dokumentation & Lineage: dbt generiert aus dem Code heraus eine Dokumentation inklusive eines visuellen Lineage-Graphen. Wir sehen auf einen Blick, welches Gold-Modell von welcher API-Quelle abhängt. Das schafft Transparenz, die man sonst nur von teuren Enterprise-Governance-Tools kennt.
Ausblick
Wir haben die Rohdaten nun erfolgreich angebunden (Teil 2) und in verwertbare Business-Logik transformiert (Teil 3). Doch wie stellen wir sicher, dass all diese Prozesse in der richtigen Reihenfolge, zum richtigen Zeitpunkt und absolut zuverlässig ablaufen? Im vierten Teil unserer Serie widmen wir uns dem Thema Orchestrierung.
Wir zeigen, wie wir die verschiedenen Bausteine unserer Plattform zu einem reibungslos funktionierenden Gesamtprozess verknüpfen.
Bleibt dran!