Enterprise Data Platform with Databricks Part 3
Introduction
Welcome back to our blog series on building modern enterprise data platforms!
In our latest post, we demonstrated how we load raw data from APIs into the Bronze Layer of our Databricks platform in a flexible and fail-safe manner. But raw data alone does not create business value. The next logical step is data transformation.
In this article, we’ll show you how we use dbt and the Medaillon architecture to transform raw data into valuable business insights.
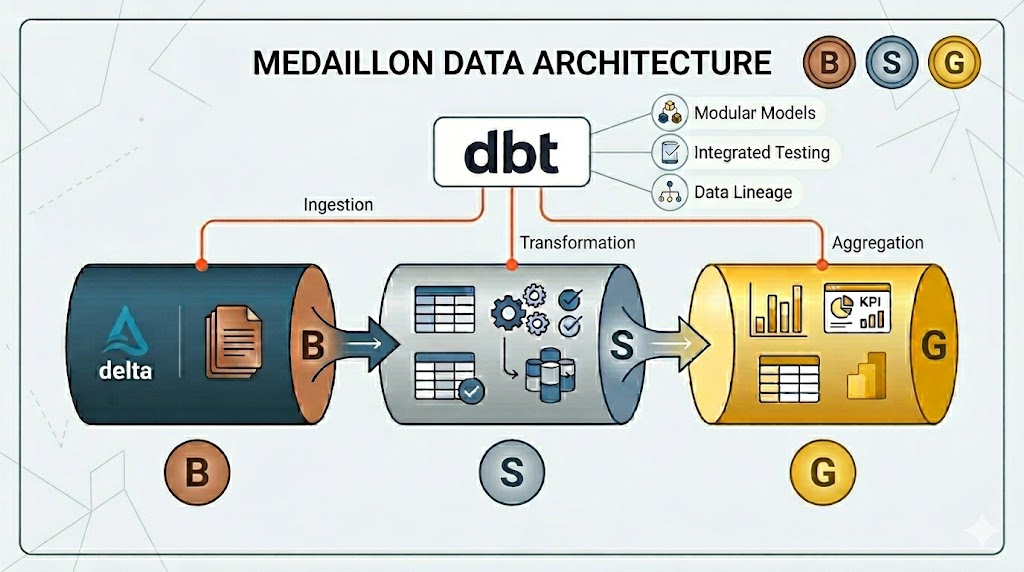
Visualization created with the help of AI (Gemini)
Medallion Architecture
Once the data has been persisted in the Delta Format Layer, our focus shifts from data ingestion to data transformation using dbt. While we used Python and Spark to connect to the APIs, dbt is now the tool we use to implement the transformation logic within Databricks.
To do this, we rely on the proven Medaillonarchitecture : We start with the raw data from the source systems (Bronze Layer) and process it step by step (Silver Layer) until we reach the finished end product (Gold Layer). Below, we’ll take a closer look at the individual layers of the Medaillon architecture:
- Bronze Layer (Raw Data): This is our “Single Source of Truth”. Here, we store the data exactly as it is delivered by the API, with only minimal technical adjustments. The focus is on completeness, audit trail integrity, and auditability. By using the delta format, we ensure that we can always access previous versions (time travel) in case business logic needs to be adjusted later on.
- Silver Layer (Cleansed): This layer is where the technical transformation takes place. We harmonize data types, implement priority rules for duplicates from different source systems, create business rules, and thereby map the raw data to the target data model. The result is a cleaned, normalized, and consistent data model.
- Gold Layer (Business Ready): The final stage of the transformation is focused entirely on business value. Depending on the use case, this stage involves aggregating data for reporting purposes or calculating business-critical key performance indicators (KPIs). The Gold Layer provides table formats that are directly optimized for reporting tools such as Power BI or Tableau.
Why dbt is indispensable for us in this CloudStack
While Databricks provides the computing power and storage architecture, dbt serves as the “brain” behind our data transformation.
- Modularity & Macros: Instead of writing huge SQL scripts, we break the logic down into small, reusable building blocks (models). We use Jinja-based macros to automate repetitive tasks - a software development principle that significantly improves maintainability.
- Integrated Testing Framework: Quality isn't a matter of chance. We define tests directly in the models' YAMLconfigurations. With every build, dbt automatically checks for unique, not_null , or referential integrity. If a test fails, the subsequent process is stopped before incorrect data makes it into the reports.
- Automated Documentation & Lineage: dbt generates documentation directly from the code, including a visual lineage graph. We can see at a glance which gold model depends on which API source. This provides a level of transparency that is otherwise only found in expensive enterprise governance tools.
Outlook
We have now successfully connected the raw data (Part 2) and transformed it into usable business logic (Part 3). But how do we ensure that all these processes run in the correct order, at the right time, and with absolute reliability? In the fourth part of our series, we’ll focus on the topic of orchestration.
We’ll show you how we integrate the various components of our platform into a seamless, end-to-end process.
Stay tuned!