Enterprise Data Platform with Databricks, Part 1
Anyone looking to build a modern data landscape today is faced with a veritable jungle of technologies, languages, frameworks, and platforms, all of which promise to be the panacea for complex data problems.
To keep track of all these options, you should first be able to answer some basic questions about your own business case:
- How complex is the data?
- What technical and regulatory requirements must be met?
- How short is the required time-to-market window?
- Should the platform be operated on-premises, in a cloud-native environment, or in a hybrid environment?
- Should an optimized, proprietary ecosystem be used, or is the flexibility of an open-source standard preferred?
Visualization created with the help of AI (Gemini)
The Backbone: Enterprise Data Integration with Ab Initio
For us, the rule is: the more complex the transformation logic, the greater the heterogeneity of the data landscape, and the more frequent the structural changes in source systems, the more Ab Initio demonstrates its strengths.
Precisely where business-critical reports, complex regulatory requirements, parallelized processing of massive amounts of data and seamless data lineage are indispensable, Ab Initio plays in a league of its own.
As a long-standing partner of Ab Initio with in-depth experience in implementing Ab Initio projects for enterprise customers, we support our customers in fully exploiting this potential.
Alternative Approaches: Agility and Cloud-Native Speed
Customer requirements are changing: A cloud-native tech stack is often required to keep pace with the dynamics of modern data landscapes.
The requirements include short development and release cycles, minimal time to market, and the ability to access data from various sources as quickly as possible.
For this specific use case, we apply our proven warehouse architectures from the enterprise environment within a modern cloud data stack. This allows us to strategically expand our technological capabilities so that we have the right solution for every requirement.
The combination of Databricks and dbt allows us to transform these proven principles into a highly flexible, agile, code-centric cloud environment.
One of the key advantages is how easy it is to set up both platforms: a fully functional development environment can be deployed in less than an hour, which significantly shortens the path from concept to live data flow.
The focus is on Python and SQL, two languages that are based on a very broad knowledge base in the market.
Despite the rapid pace of development, quality does not suffer: Thanks to dbt’s integrated testing and lineage frameworks, automated quality checks are built directly into the development process.
This ensures that the expertise in data governance that our enterprise customers have come to expect is maintained even in agile cloud projects.
The MVP Project: Building a Cloud Data Platform in Record Time
We asked ourselves: How quickly can a robust lakehouse architecture concept be implemented in a modern cloud stack, and which features are essential for such an MVP project?
Our goal was to ensure that, despite a minimal time-to-market, all core components of a professional enterprise solution were covered:
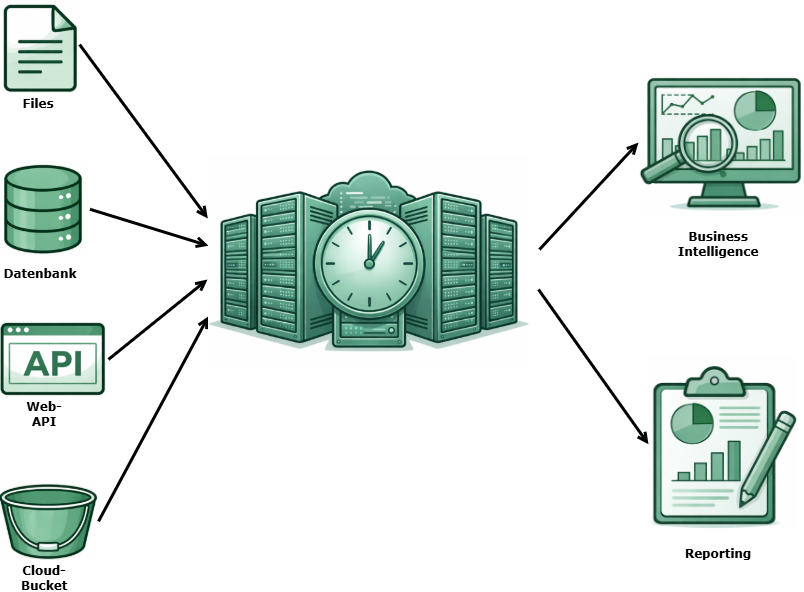
- Ingestion: Integration with external APIs and access to cloud buckets are handled via Spark scripts.
- Layer Architecture The consistent separation of processing logic into Bronze (Raw), Silver (Cleansed), and Gold (Business) layers within Databricks.
- Business Logic & Transformation: Once the data is in the Lakehouse, we use dbt for all transformations. This not only ensures clean code, but also provides a built-in testing and lineage framework.
- Job Scheduling & Orchestration: Databricks Workflows fully automate the entire process, from the API call to the finished data model.
- Testing & Lineage: Using the testing framework integrated into dbt, we perform automated quality checks and also provide a comprehensive visualization of the lineage.
- CI/CD-Integration: To simulate real-world release cycles, the entire stack was deployed using modern CI/CD pipelines, leveraging Databricks’ Asset Bundle functionality.
Our MVP project demonstrates that we not only have a firm grasp of the complex world of Ab Initio, but are also experts in Databricks and modern cloud stacks.
We know how to bridge the gap between governance-heavy enterprise requirements and rapid cloud development without compromising on quality or stability. We don’t just deliver code—we deliver architectures that stand the test of time.
Outlook
In the following blog series, we provide a detailed look at the implementation of the core components of the MVP project. We’ll start with ingestion—connecting to external APIs and accessing cloud buckets.